通訳案内士試験
先週のLL Planetsに引き続き、今週末は通訳案内士の試験で、来週末、さ来週末とこのところ予定が目白押しですが、
去年に引き続き、28日に通訳案内士の一次試験に挑戦しました(このブログを書いているのは30日)。
今年は、昨年受かった地理と一般常識が免除になり、英語と歴史を受験しました。
通訳案内士の試験ですが、地理、歴史、一般常識がマークシートで問題用紙を持ち帰ることができます。
地理、歴史、一般常識は平均点を取ればよいので甘く考えていたのですが、今年の歴史はだいぶレベルが高く私の得点も微妙で、『また来年』ということになりそうです。
一方で、英語の試験ですが、記述式で試験終了後問題用紙も回収されますのではっきりしたことはいえませんが結構出来が良かったです。
もっとも、問題が去年と比べて易しくなったようで、例えば英作文の場合、『バレンタインデーとは何か?』を80ワード程度の英語で書かせる問題だったのですが、今年は『女性専用車を3,4行(恐らく30~40ワード程度)で説明せよ』、『こいのぼりを3,4行で説明せよ』とかだいぶ問題の難易度が下がったかと思います。80ワードでの作文と40ワード程度×2だと、当然80ワードで書く方が深く説明しなければならないので難易度が高いかと思います。もっとも簡潔に必要事項をまとめるということであれば逆に難易度が高くなりますが問題文からはそう深堀も出来ないかと思うので簡単になったかと思われます。
英語の合格基準は『平均点を60点とした場合に70点を合格とする』とよく解らない基準で、平均点より10点以上上回ると合格というイメージのようなので、私の英語力を鑑みるとこちらも通るかどうかは微妙です。しかし、2年も英語の勉強を続けているとさすがにそれなりに上達するもので、来年は合格に手が届きそうです。と手ごたえを感じただけでも良かったです。
場合によっては歴史が落ちて、英語が通るということもありえるのですが、そうなると歴史の方をだいぶ軽視し英語の勉強ばかりをしていたので少し悔いが残ります。
2011-08-30 | コメント:0件
[ADP開発日誌]0.74リリース マルチスレッド化の第一歩 & LLPlanets発表用リリース
ADP公開一周年記念記事がまだ途中ですが、
Ver0.74のリリースを行います。
Ver0.74は、Accessでの整数のインサート時のエラーの改修と、pipe述語の実装があります。
pipe述語というのは、以前話に出ました、マルチスレッド機能の1つでパイプライン処理を実現する述語になります。
ちなみに、本リリースにに基づき、LLPlanetsのライトニングトークで発表を行います。私を見かけた人は『ブログ見てます』と声を掛けていただければうれしかったりします。
では、pipe述語の使用例を見てみましょう。何回かやっていて最近ホットなSQLのパフォーマンスについての例になります。
関連記事1:[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011
関連記事2:SQLの実行パフォーマンスについて 2010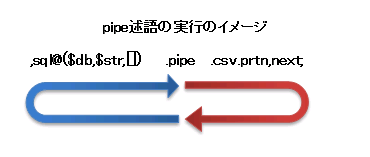 図で、青の矢印の部分と赤の矢印の部分がそれぞれ別のスレッドになっており平行で動作しています。
pipe述語が無い場合の動作イメージは以下のとおりです。
図で、青の矢印の部分と赤の矢印の部分がそれぞれ別のスレッドになっており平行で動作しています。
pipe述語が無い場合の動作イメージは以下のとおりです。
 比較してみますと分かりますが、sql述語~next述語まででループがありますが、それを2つに分けて実行するイメージになります。
UnixのシェルやWindowsのコマンドプロンプトで、|(パイプ)を使ってコマンドをつなげることがありますが、pipe述語の実行イメージはこれと同様になります。
シェルのパイプ(|)は20年以上前からあり、お手軽にマルチタスク処理を実現できるのですがプログラム言語レベルで使えるものがなく、マルチスレッドプログラムとなるとなぜかややこしくなります。
ADPではお手軽にマルチスレッドプログラムを体験して頂くため、その一つとしてパイプを実装しました。
実行時間は、約108秒で、約9%速くなっています。少しですが実験3よりも速くなっていることが解ります。
比較してみますと分かりますが、sql述語~next述語まででループがありますが、それを2つに分けて実行するイメージになります。
UnixのシェルやWindowsのコマンドプロンプトで、|(パイプ)を使ってコマンドをつなげることがありますが、pipe述語の実行イメージはこれと同様になります。
シェルのパイプ(|)は20年以上前からあり、お手軽にマルチタスク処理を実現できるのですがプログラム言語レベルで使えるものがなく、マルチスレッドプログラムとなるとなぜかややこしくなります。
ADPではお手軽にマルチスレッドプログラムを体験して頂くため、その一つとしてパイプを実装しました。
実行時間は、約108秒で、約9%速くなっています。少しですが実験3よりも速くなっていることが解ります。
実験1~3どの場合でも、pipe述語が有効だということが分かります。これは、
・DBMSからデータを取得する
・ファイルへ書き出す
という2つのIO処理があり、pipe述語によって、それらを同時に実行することが出来る為です。
また実験2-PPと実験2-Pを比べても分かりますとおり闇雲にマルチスレッド化しても高速化が図れない場合もあります。
パフォーマンスアップは様々な要素が関わってきますので実験により確認しながらということが必要になります。
pipe述語はお手軽にマルチスレッドを実現でき、また取り外しも楽なので簡単に実験や試行錯誤が出来ます。
ADPのpipe述語はキャッシュ機能と同様に便利な道具として利用できるかと思います。
また、実験1-P、2-P、3-Pを比較しますとどれをとってもパフォーマンスにあまり差がないことがわかるでしょう。ADPの開発にあたりプログラマの自由度を高めるということも考慮しています。つまり、『○○でなければダメ』ではなく、どのアルゴリズムを採用するかはプログラマーの判断で、いか様にも選択できるような言語を目指しています。
追記:コメント欄での指摘およびテスト再現性を考慮してテスト環境を整備して再度計測しています。
関連記事2:SQLの実行パフォーマンスについて 2010
実験環境
JOINのパフォーマンス実験環境はこちらに記述しています。実験1 素直にSQL側でjoinをさせたものを実行(再掲)
例により、SQLで素直にjoinさせてみます。以下のようなコードになります。,$db = "DSN=Trade"
,$str = "SELECT Price.CODE, RDATE, OPEN, CLOSE, NAME FROM Price "
"INNER JOIN Company ON (Price.CODE = Company.CODE)"
,sql@($db,$str,[]).csv.prtn,next;
[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011の実験1と同じです。
実行時間も同じで、約119秒です。
実験2 ADP側でjoin(ネステッドループ&キャッシュ)
続いて、ネステッドループjoinをADPのキャッシュ機能を使って高速化をはかります。,$db = "DSN=Trade" ,$price = "SELECT CODE,RDATE,OPEN,CLOSE FROM Price" ,$company = "SELECT NAME FROM Company WHERE CODE = ?" ,sql( $db, $price, [], @rec) ,pipe ,sql( $db,$company, [$rec[0]], $name) ,csv($rec,$name).prtn,next;[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011の実験2-Bと同じコードになります。 実行時間ですが、約117秒となりました。実験1と比べて約1.6%程速くなっています。
実験3 ADP側でjoin(事前にマップ作成)
3つ目は、ADPでも事前にマップを作成し、joinを行うことができます。,$db = "DSN=Trade"
,@tbl = {}
,sql($db, "SELECT CODE,NAME FROM Company",[], @r)
,@tbl = @tbl + [ $r["CODE"] | $r["NAME"] ]
,next
,sql($db, "SELECT CODE,RDATE,OPEN,CLOSE FROM Price",[],@rec)
,$key == $rec["CODE"].str
,csv($rec,$tbl[$key]).printn,next;
[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011の実験3と同じコードです。
実行時間ですが、約111秒で実験1より7%ほど速くなっていることが解ります。
続いて、pipe述語を使って並行処理をさせてみます。
実験1-P 素直にSQL側でjoinをさせたものをpipe実行
実験1のコードにpipe述語を挿入しています。,$db = "DSN=Trade"
,$str = "SELECT Price.CODE, RDATE, OPEN, CLOSE, NAME FROM Price "
"INNER JOIN Company ON (Price.CODE = Company.CODE)"
,sql@($db,$str,[]).pipe.csv.prtn,next;
実験1のコードとの違いは4行目の
,sql@($db,$str,[]).pipe.csv.prtn,next;
のpipeという記述で、これがpipe述語になります。pipe述語で区切られたコードは並行で処理を行います。
つまり
,sql@($db,$str,[])
の部分(バックトラックの実行)と
.csv.prtn,next;
の部分は並行で動作します。
sqlの部分は、.csv.prtn,nextの実行中にバックトラックを行います。
next述語で、pipeまで戻りますと、sqlの実行を待ち(同期)データを受け取ります。
ややこしいかも知れませんが、図で示すとよくわかるかと思います。
図で、青の矢印の部分と赤の矢印の部分がそれぞれ別のスレッドになっており平行で動作しています。
pipe述語が無い場合の動作イメージは以下のとおりです。
比較してみますと分かりますが、sql述語~next述語まででループがありますが、それを2つに分けて実行するイメージになります。
UnixのシェルやWindowsのコマンドプロンプトで、|(パイプ)を使ってコマンドをつなげることがありますが、pipe述語の実行イメージはこれと同様になります。
シェルのパイプ(|)は20年以上前からあり、お手軽にマルチタスク処理を実現できるのですがプログラム言語レベルで使えるものがなく、マルチスレッドプログラムとなるとなぜかややこしくなります。
ADPではお手軽にマルチスレッドプログラムを体験して頂くため、その一つとしてパイプを実装しました。
実行時間は、約108秒で、約9%速くなっています。少しですが実験3よりも速くなっていることが解ります。
実験2-P ADP側でjoin(ネステッドループ&キャッシュ)でpipe実行
続いて、実験2のコードにpipe述語を挿入しています。,$db = "DSN=Trade" ,$price = "SELECT CODE,RDATE,OPEN,CLOSE FROM Price" ,$company = "SELECT NAME FROM Company WHERE CODE = ?" ,sql( $db, $price, [], @rec) ,pipe ,sql$( $db,$company, [$rec[0]], $name) ,csv($rec,$name).prtn,next;実行時間は、約89秒で実験2と比べて約24%速くなっています。 興味深いのは実験1-Pよりも速度向上が大きいです。pipe述語は半分に分割してそれぞれ実行するという方式をとっていますが、当然ですが常に半分になるとは限りません。上手く半分に分割できる場合もありますし、そうでない場合もあります。そのような関係でこのような逆転現象が発生します。一口にJOINのパフォーマンスといってもこのように様々な要因が絡んできますので、一概に『○○が効率的』といえないことを表す良い例となっています。
実験2-PP ADP側でjoin(ネステッドループ&キャッシュ)でpipe実行2
実験2-Pのコードにさらにpipe述語を挿入しています。pipe述語は1つだけでなく複数入れることもできます。,$db = "DSN=Trade" ,$price = "SELECT CODE,RDATE,OPEN,CLOSE FROM Price" ,$company = "SELECT NAME FROM Company WHERE CODE = ?" ,sql( $db, $price, [], @rec) ,pipe ,sql$( $db,$company, [$rec[0]], $name) ,pipe ,csv($rec,$name).prtn,next;実行時間は、約112秒で実験2-PPと比べて逆に遅くなっています。このように闇雲にマルチスレッドを行っても必ずしも速くならない場合がある(もちろん速くなる場合もある)のが面白いところです。pipe述語を2つ使うと3つスレッドが動作しますが、実験環境ではCPUコアが2つしかないので足の引っ張り合いのようなことになったようです。
実験3-P ADP側でjoin(事前にマップ作成)でpipe実行
続いて、実験3のコードにpipe述語を挿入しています。,$db = "DSN=Trade"
,@tbl = {}
,sql($db, "SELECT CODE,NAME FROM Company",[], @r)
,@tbl = @tbl + [ $r["CODE"] | $r["NAME"] ]
,next
,sql($db, "SELECT CODE,RDATE,OPEN,CLOSE FROM Price",[],@rec)
,$key == $rec["CODE"].str
,csv($rec,$tbl[$key]).printn,next;
実行時間は、約91秒で、実験3と比べて約18%速くなっています。
ちなみに実験3-Pからさらにpipeを挿入しても良いのですが、実験2-Pの時と同様にあまり速くならないので省略します。
結論
各実験結果を示します。| 実験 | 実行時間(秒) |
|---|---|
| 実験1 | 119 |
| 実験2 | 117 |
| 実験3 | 111 |
| 実験1-P | 108 |
| 実験2-P | 89 |
| 実験2-PP | 112 |
| 実験3-P | 91 |
2011-08-19 | コメント:0件
真のソフトウェアエンジニアに必要なモノ(SQLは銀の弾か?)
件の社長ですが、ブログで、まとめ記事を出しております。あれだけ口悪く私のことを煽っていたのにバツの悪い終わり方だと思いますが、まぁ、これ以上、『SQLはオブジェクト指向言語の数十倍の効率』の件を追求する必要もないのでその件は終わりにします。
ただ、私の方ですが、久しぶりに火がついたので気ままに書いてみます。もっとも粘着質といわれるのも嫌なので、件のブログ自体にはコメントしません。が別に書いていることが正しいとも思っていません。件のブログですが、コメント欄が消されていますので、疑問等ある人はこちらのコメント欄にでも書いて頂ければ『私に答えられること』でしたらコメントします。
素直さは如何に大切か、とか、騙されないようにする為に(適切な議論の方法)と記事を書いてきましたが、そもそも論として、ソフトウェア開発に関連した技術面で何か記事を書くのであれば、それは技術者を代表してという立場で発言することになるでしょう。ここでの技術者の代表とは、『ソフトウェア開発をリードし設計、開発、テスト、トラブルシュートを行い、単なる知識だけでなく頼れる技術を持った、顧客だけでなく共に働く人や競合他社からも一目置かれるような人』ということで話をします。お前はどうやねんとツッコミが来そうですが、私は僭越ながらその末席において頂いていると思っております。
というわけで、以下、真のソフトウェアエンジニアとって必要なモノについて語ってみましょう。
『銀の弾などない』ことを理解する
恐らくソフトウェアエンジニアだけでなく、顧客の情報システム部の方や、現代では企業経営者全ての人に教養としてお薦め本に『人月の神話』があります。私はざっと一読しまいたが、ソフトウェア開発の真実をみることができるでしょう。ちなみに訳本のせいか私にとっては少々読みにくい(というかくどい)です。 その中にある、『銀の弾などない』という章で著者のフレデリック・ブルックス氏は『ソフトウェア開発においては○○を使えば生産性や信頼性、安全性が著しく向上したりするという特効薬は存在しない』という趣旨のことを主張しています。この主張は約25年前になされましたが、今でも充分に通用するでしょう。つまり、「○○を使えば生産性がX倍向上します。」ということを耳にするかと思いますが、『そんなものはない』というのが氏の主張で、私も自身の体験からこの主張は現在のところ正しいと思っています。 ひょっとしたら経験は浅いが技術力のある方の中には「そんなことはない、銀の弾はある!」と思うかもしれません。一経験者から言わせてもらうと恐らくそれは思い込みです。 ただ、この主張が将来に渡っても正しいかどうかは解りません。なぜかというとこの主張は現在のソフトウェア開発の弱点とそれが将来に渡って解消されないという予測を行っているだけだからです。人間という生き物は欲深いものでこの弱点を克服しようと多くの人が日々努力しています。私がADPを開発しているのもまぁそういう努力の1つです(と言っておきましょう)。 当然ですがフレデリック・ブルックス氏もその点はきちんとフォローされており、約25年前に、銀の弾の候補の一つとしてオブジェクト指向プログラミング(OOP)を挙げておられます。ただ、その約10年後に出された『「銀の弾などない」再発射』ではオブジェクト指向が本来使われるべき領域(業務ロジックにオブジェクト指向の適用)ではなく低レベルな部品レベル(リストクラスやGUI等)にとどまっていると指摘しています。 現在ですが残念ながら状況はあまり変わっていないでしょう。オブジェクト指向はだいぶ浸透してきたかと思いますが、現在ではソフトウェア開発期間に求められる時間が短くなってきています。つまり顧客はカジュアルにサービスを立ち上げたがります。そうなるとじっくりと開発するというわけではなくありものでちょちょっと作ることになり、OOPといっても『ライブラリを使う』ということはあっても業務ロジックを作ることはそう多くはないでしょう。また何よりOOPを使った失敗プロジェクトも多かったのも事実です。 そして、件の社長ですが、『少なくともRDBを使う業務アプリの開発において、データを操作する部分に関してはSQLは銀の弾になりうるのではないか』と主張しているのかと想像します。行間を読む
ソフトウェアエンジニアは普段コンピュータばかりを相手にしているのでどうしても理屈っぽくなり、言葉を額面どおりに取る傾向にあります。がソフトウェアエンジニアたるものコンピュータばかりでなく人間も相手にしなければなりません。行間を読むことは人間同士のコミュニケーションで重要なことです。がもちろんですが相手に行間を読んでもらう前提で話をしてはいけません。コミュニケーション能力は技術者というより人間としての経験値が必要ですが、幸い今ではインターネットを使ったコミュニティが豊富にあります。行間を読む訓練は昔より遥かに簡単にできるでしょう。SQLは銀の弾になりえるか?
という訳で、まとめ記事ありました、件の社長が本当に言いたかったことを推測してみますと、 『少なくともRDBを使う業務アプリの開発において、データを操作する部分に関してはSQLは銀の弾になりうるのではないか? 銀の弾ではなかったとしてもオブジェクト指向プログラムより使える技術だろう』 ということが某社長が言いたかったのかと仮定します。 で『その根拠』について私の経験を元に考えてみましょう。ちなみに、『人月の神話』にはSQLは銀の弾の候補に上がっていませんでした(間違っていたらコメント欄にご指摘下さい)。 この点については社長自信、色々上げておられるのですが、私の経験上一番納得できるポイントは ・オブジェクト指向技術を使ったプロジェクトが失敗したときの被害 と ・SQLに頼ったプロジェクトが失敗したときの被害 とを比較した場合、どちらがより被害が大きくなるか?です。 件の社長が言いたいのは(というか過去の議論で私が理解できた社長の主張は)『OOPを使ったプロジェクトが破綻した場合の方がより被害が大きい。』ということでした。私の中では『どっちもどっち』と思う面もなくはないですが、確かに実際に聞く話は『OOPを使ったプロジェクトの破綻』が多いし深刻度が高いです。もっとも私の周り3メートルの範囲ですが。 この事実は、単純に『OOPが銀の弾候補』になり、それ以外にもオブジェクト指向がバズワードとして色々宣伝されたので、多くのチャレンジャーが集まり、壮大な実験の結果、失敗例が集まったということかと思われます。 その他、OOPが思ったほど実力がないということの例を挙げますと統合開発環境の存在があるでしょう。本当にOOPが銀の弾なら統合開発環境は要らないでしょう。皮肉な話ですが統合開発環境が高機能になればなるほどOOPがそれ程たいしたことではないという風に聞こえてしまいます。例えば、「統合開発環境のリファクタ機能を使えばそんなの簡単です。」という話を聞きますと、すごいのは統合開発環境であって言語ではないということでは?と疑問が出てきます。ちなみに「統合開発環境がないと開発できない」とか言われると『本末転倒やん』と嘆きたくなります。 さらに別の例ですが、私が関わったプロジェクトでC++を使ったものがあったのですが、バグ入りのものをリリースしたが、既に担当者がいなくなったので修正が出来ないということで私に助けを求めたものがありました。単純にOOPで作られたというだけでなく、マルチスレッドで動作していたのでバグの原因が不明で誰も手が付けられなかったということでした。OOPの思想の1つにカプセル化(隠蔽、ブラックボックス化)があります。確かにバグがないプログラムを再利用する場合はカプセル化は理想的です。しかし、そのカプセルの中にバグがある場合は否応なく内部を調べる必要があり、これにプラスして経済的な制約が加わると大変なことになることは想像できるでしょう(まぁ私は儲かるのですが・・・ちなみにこういうことでお困りの方がおられたら私ならなんとかできるかもしれません)。 ここまで言いますと『じゃなんでお前はC++を使っているんだ』とツッコまれそうですが、道具はあくまでも道具で、適切に使えば良いという話だけです。長所、短所を理解した上で使えばよいでしょう。ちなみに私が単独でプログラムを記述する場合はC++をメインで使いますが(もっとも最近はADPがメインですが)、誰かに引き継ぐ前提のプログラムの場合、関わるメンバを見て言語を選択します。そして、私の半径3メートル以内ではC++を使うことは残念ですがあまりなかったです。 一方でSQLに関してですが、さすがに長年の実績がある言語で、例えばパフォーマンス上で問題が発生した場合、様々な解決策(ノウハウ)があります。また私の半径3メール以内でも多くの人がSQLを使っています。SQLが出来ない人は少ないです。最近では、あるSQLが遅くて色々試行錯誤していましたら、一緒に働いている方から「何か知らんがこうすれば速くなった」とアドバイスを受け実際に速くなったケースがあります。大人の事情で具体的な詳細は明かせませんが、そういうことは皆様の回りでも現実に多々あるでしょう。こういうことを言うと「実行プランをきちんと解析せいや」とかお叱りを受けますが当然そんなこともしております。 もちろん、SQLをどうこねくり回しても解決できないこともありますが、その場合でも案外ベタな解決方法(私のブログで紹介しているようにJOIN崩しとか、その他非正規化とか)があり、この辺りに関しては知る人ぞ知るという感じで、私の回りでは結構あるあるネタになっています。 このような言語自体の性質および実績から来る信頼性は追い込まれたエンジニアにとってはありがたい存在で、「SQLは良い」という意見については反対する気はないです。ただ、「SQLが効率的」といわれると普段から遅いSQLを速くするという作業も行っている身としては?と思うわけです。 またMDXという言語を知ってからは、JOINしながら集計することに関してはMDX(OLAP)の方がSQL(RDB)より強力という認識でおります。道具はやっぱり適材適所で過信はいけません。 業務アプリ限定で言いますと、SQLとOO言語を混ぜて使う必要があるために、SQLとOO言語のパラダイムの差を吸収する必要があるでしょう。いわゆるインピーダンスのミスマッチで、その解消策の1つとして『OO言語で統一する』という試みが昔から行われています。古くはオブジェクト指向DBなどで、今ではO/Rマッパーなんかですね。ここで某社長の思いの行間を読むと「OO言語に統一できるという考えがファンタジーだ!」ということで、その根拠にN+1問題をあげておられます。ちなみに「SQLはオブジェクト指向言語の数十倍の効率」自体は間違った主張ですが、その行間を言い直すとN+1問題ということになります。N+1問題はググれば出てきますし、私がSQLの実行パフォーマンスについて 2010で指摘した実験2は原理的にN+1問題と同じになります。 そして社長は「オブジェクト指向側に寄せるより混ぜて使うことを前提に上手く開発できるようなスタイルを確立すべし」ということが言いたいのでしょう。まぁ適材適所ですね。 ちなみに『OO言語とSQL(リレーショナルモデル)とのパラダイムの差を吸収することは難しいが、述語理論とSQL(リレーショナルモデル)との差はあまりないのでSQLを呼び出す言語を述語理論に基づいた言語にすれば上手くいくのでは』というのが私の仮説になります。 もう1つうんちく次いでに語りますと、「SQL系の言語で統一する」という試みもありました。4GLとか言っていたものです。これは早々に消えたかと思います。4GLが宣伝されていたとき、私はあまり関わっていませんでしたが「SQLでGUI」と言われても『どう組むんや!』ということは明白で、まぁやっぱり道具は適材適所なのでしょう。 「オブジェクト指向プログラミングが銀の弾かどうか?」というのはまだ結論が出ていないかと思いますが、最近では関数型の言語が一部ではクローズアップされています。ちなみにADPがベースにしているPrologという言語は述語理論を基礎においています。私は述語理論を押しているわけです。先のことはわかりませんが、オブジェクト指向プログラミングが昔の構造化プログラムと同じ道を行き、将来別のパラダイムがスタンダードになっているかもしれません。もちろんRDBが駆逐されているという世界もあるかもしれません。つまらない意見ですが、まぁ先のことはわかりません。 そして「SQLは銀の弾か?」と言われると『データを扱う上では候補ぐらいにはあげてもよいけどSQLはそもそもドメイン固有言語ではなかったですか?』。というのが私の意見になります。 以上、行間を読んで書いてみましたが、如何でしたでしょうか? がんばりましたがさすがにSQLを持ち上げるのは厳しいです。つまらない結果ですがまぁ現実はこんなもんです。 最後に1つだけコメントしますと、このように書けば炎上はしませんが、多くの共感は得られるのではと思うのですが、まとめ記事では残念なことに主張すること自体を取り下げたようです。 いったい、彼は何が言いたかったのでしょうか?
2011-08-18 | コメント:2件
騙されないようにする為に(適切な議論の方法)
素直さは如何に大切かという記事を書いたのですが、考えてみれば『それは私自身にも当てはまるのでは?』というツッコミがきそうですし、何よりこれはエンジニア向けに書いているので『判別つかない議論をどうすれば見極めれるのか?』とか『自身がどういう姿勢で臨めばよいのか?』という全うな質問もあるかと思います。
そこで、ITエンジニアが適切に議論(主張)を行う方法をメモしてみます。
1.自分の主張が正しことの裏を取る
もっとも大事なことは自分できちんと根拠を示すことです。では根拠となるのはどういったものでしょうか?
(1) 実験する
例えば、『○○の方が速い』ということでしたら実際に実験してみればよいのです。実験というのは何より客観的ですのでその結果は事実として受け止める必要があるでしょう。ただ、実験では『たまたま自分のマシンでは速かった』ということもあるでしょう。したがってその実験が再現できるよう環境もあわせて提示しましょう。
SQLの実行パフォーマンスについて 2010ではこの方針にのっとって主張を行っています。
(2) 論理的な考察
実験にプラスしてそれを補う理論的な考察も必要でしょう。ここで重要なことは、IT周りの議論が起こったとき理論的な考察というのに無理がある場合があることです。つまりITの世界は数学のように割り切れない面もあります。パフォーマンスという一見簡単な問題にしても純粋な数学からすれば充分に複雑です。いわゆる複雑系というやつです。それ以外でも例えば、工数が少なくなるというのはそもそも主観が入るでしょう。そのような場合は出来るだけ問題を簡単にして説明可能な実験に分割してそれぞれ実験を行えばよいでしょう。
[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011ではこの方針にのっとって主張を行っています。
(3) 他のソースの引用
確からしい他のソースから引用するのももちろん良いでしょう。その場合引用元を開示すれば他の人が検証可能となります。この場合注意したいのはインターネットの情報はウソもあるということです。騙されないようにする必要があるでしょう。
2.騙されない為のテクニック
ITエンジニアたるもの技術的な論争についてはきちんと処理をしたいところです。口頭での議論だとついつい煙に巻かれることもありますが、ネット上ですと文章として残っていますので冷静に対応すればよろしいかと思います。
(1) 発言者の過去の発言を検索し矛盾がないか検証する
残念ながら論理的に筋道が通った話ができない人がいます。また人というのは時間と共に考え方が変わります。相手の発言はそのようなことを考慮しているかどうかを検証する必要があります。その際にあらかじめ公開の場で質問をしておくと後々それが助けになります。
件の社長は、炎上したのでまとめ
で、
『SQLはオブジェクト指向言語の数十倍の効率』
という発言し、その根拠にコメント欄で、JOINの例を挙げたが、その一年後にツイッターで、
『JOINをなくすならAPサーバでキャッシュする。 集計関数をなくすなら、ORDER BYを禁止する。 SQLがイヤならRDBMSは使わないこと。 何度も書いているけれど、SQLで出来ることをAPサーバでやっても、【絶対に】DBサーバの負荷は減らない。 ただし、下手糞を除く。』
と発言しています。そしてそれを指摘すると今度は、シビアな設計で、
『JOINするしないでは、トレードオフの関係は、すべてのリソースに対して技術者の技量しかありません。』
といっています。発言に矛盾があることはもうお分かりでしょう。
(2) 質問に答えない
少なくとも明らかな素人を除いて、質問に答えない(そして中傷してくる)相手はその質問自体に答えたくないのでしょう。
SQLの実行パフォーマンスについて 2010で私は件の社長本人に『SQLはオブジェクト指向言語の数十倍の効率』の考えは変わったのか質問しましたが、件の社長はそれには直接答えていません。逆に質問してきたり、独自の認定を行い、議論を終わらせたりします。少なくとも自己の主張が正しいとするならば質問には答えられるはずです。
(3) 綺麗な図に惑わされない
これは一部の方に行われているが綺麗な図や表を用いてさも正しいという風に見せ付けることがあります。いくら綺麗にまとまっていても真のITエンジニアたる者だまされてはいけません。よーく検証しましょう。
例えば、以下の図ですが、

一見綺麗にまとまっているでしょう。しかし、データ転送量の欄を見てみましょう。 『データ転送量 トラフィックに影響 JOINした方が少ない 』 とあります。これが成立しないことは、[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011で指摘しています。一見すると綺麗な表でまとめられているので気がつかないかもしれませんが、きちんとみれば分かります。また他の項目についてもきちんと説明せずに結果だけが表になっていることが分かります。 3.議論をする上での心構え 本来議論というのは、炎上をねらったり、闇雲に自己主張をするのではく、自己の見聞を広めたり、起こった事象に対して深い考察を行ったりするものであると考えます。 (1) 議論は勝ち負けではない これがぜんぜん解っていない人がいます。議論で相手を言い負かすとか論破するとかは少なくともITの分野では意味がありません。 (2) 相手の主張に耳を傾ける 自己の主張に反論してくる人は、ある意味ありがたい人です。相手の主張を受け入れ真摯に答えましょう。私は、SQLの実行パフォーマンスについて 2010で、「OO言語側の最適化が不十分である可能性がある」と結論付けていますが、これはつまり一見すると『SQLはオブジェクト指向言語の数十倍の効率』ということが正しいと思える場面が存在することを認めています(その上でそれは視野の狭い経験にしか基づかないという指摘を行っています)。 (3) 相手に感謝する、発言を憎んで人を憎まず 議論を行った後は相手に感謝の意を表する必要があります。私自身、SQLの実行パフォーマンスについて 2010という記事を書くにあたって再度勉強になりました。そういう意味では件の社長には感謝したいですが、それを『文盲のサル』と言われてしまっては腹も立ちますがそのような感情は捨てて、この場で感謝の意を表明しておきましょう。
一見綺麗にまとまっているでしょう。しかし、データ転送量の欄を見てみましょう。 『データ転送量 トラフィックに影響 JOINした方が少ない 』 とあります。これが成立しないことは、[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011で指摘しています。一見すると綺麗な表でまとめられているので気がつかないかもしれませんが、きちんとみれば分かります。また他の項目についてもきちんと説明せずに結果だけが表になっていることが分かります。 3.議論をする上での心構え 本来議論というのは、炎上をねらったり、闇雲に自己主張をするのではく、自己の見聞を広めたり、起こった事象に対して深い考察を行ったりするものであると考えます。 (1) 議論は勝ち負けではない これがぜんぜん解っていない人がいます。議論で相手を言い負かすとか論破するとかは少なくともITの分野では意味がありません。 (2) 相手の主張に耳を傾ける 自己の主張に反論してくる人は、ある意味ありがたい人です。相手の主張を受け入れ真摯に答えましょう。私は、SQLの実行パフォーマンスについて 2010で、「OO言語側の最適化が不十分である可能性がある」と結論付けていますが、これはつまり一見すると『SQLはオブジェクト指向言語の数十倍の効率』ということが正しいと思える場面が存在することを認めています(その上でそれは視野の狭い経験にしか基づかないという指摘を行っています)。 (3) 相手に感謝する、発言を憎んで人を憎まず 議論を行った後は相手に感謝の意を表する必要があります。私自身、SQLの実行パフォーマンスについて 2010という記事を書くにあたって再度勉強になりました。そういう意味では件の社長には感謝したいですが、それを『文盲のサル』と言われてしまっては腹も立ちますがそのような感情は捨てて、この場で感謝の意を表明しておきましょう。
2011-08-15 | コメント:3件
[ADP開発日誌-公開1周年記念特集 Part6] プログラミング言語の制御構造のいろいろ(4)
ちょっと余計な記事が入りましたが、続きを
C++の仮想関数の欠点
話が少し前後しますが、Part4の記事でC++の仮想関数呼び出しの仕組みについて説明しましが、ここではC++の仮想関数の欠点について指摘します。C++ではvtableというメンバ関数のアドレスを集めたテーブルを用いて仮想関数の呼び出しを実現していました。この方式は効率がよいのですが『コンパイル時に呼び出すべき仮想関数が決定しなければならない』という弱点があります。 どういうことかといいますとC++でのメンバ関数呼び出し object.virtual_method( arg1, arg2, arg3) という呼び出しで、virtual_methodというメンバ関数名はコンパイル時に参照されますが、実行時には内部的に振られた番号(vtableのインデックス)になります。つまり実行時にはこの名前は参照できません。と同時にvtableのインデックスを取得する手段もないので、実行時に呼び出すメンバ関数を選択したいということができません。 これの何が欠点かピンとこないかもしれませんが、例えば、バッチファイルからVBScriptを使ってExcelを操ったりしますが、この特にExcelのバージョンをあまり気にせずにExcelを操作(メソッドを呼び出す)するでしょう。これと同じことは、C++の仮想関数の仕組みではストレートに実装できないということです。Windowsでは皆さんご存知のとおり、COMという仕組みをOSに実装することで実行時に呼び出すメソッドを特定することを行っています。 COMというとえらく古いと思われるかもしれませんが、.NET Framkework からExcelを呼び出す場合もCOM相互運用性という仕組みを使って.NET Framework → COM → Excel という風に呼び出しいます。 話が脱線しますが、私は.NET Frameworkが廃れるのではないか? と思っていますが、その理由のひとつが .NET FrameworkがCOMやOLE DB等のようにWindows APIを充分に置き換えていないと思えるところにあります(もっとも先のことは解りませんのでなんともいえませんが)。関数の動的なロード&実行の例
場合によって呼び出す関数を変える というプログラミングテクニックは、オブジェクト指向プログラミング以外にもあります。典型的な例のひとつにデバイスドライバがあります。 デバイスドライバはご存知のとおりハードウェアとOSのAPIを橋渡しするソフトウェアでハードウェアに合わせて作成されています。ハードウェアを変えるとそれにあわせてデバイスドライバも変えます。 デバイスドライバはCで記述されることが多いです。最近のOSではPlag&Playが一般的になりましたし、USB接続機器ではOSを再起動せずに、デバイスドライバがロードされます。このような動的なソフトウェアのロードの仕組みはどうなっているのでしょうか? 続いては、公開1周年記念特集記事として『プログラミング言語の制御構造のいろいろ(5)』を書いてみます。
2011-08-14 | コメント:0件